Массовая оптимизация
Прогресс цивилизации состоит в расширении сферы действий, которые мы выполняем не думая.Алфред Норт Уайтхед, Символизм, его смысл и воздействие
Самый лучший инструмент для программирования под компьютер — это сам компьютер, и мы должны не упустить ни малейшего шанса его использовать. Просматривать графики важно, но это занимает время и включает в себя человеческий фактор. Первая же мысль программистов, обремененных подобными задачами — автоматизация. Следующая мысль обычно о том, чтобы выставить пороги, например, 1400 мс для времени загрузки страницы, и сигнал или скрипт для отправки письма при пересечении этого порога.
На каждую невыполнимую задачу найдется масса простых, очевидных и, в то же время, неправильных решений. Красные линии, приборные панели, горящие лампочки — все это очень знакомые клише из фильмов, которые призваны создавать атмосферу важности происходящего на экране. Но вообще-то, голливудские сценаристы ничего не смыслят в компьютерах. Поэтому я бы не рекомендовал брать с них пример.
С такими сигнализациями со статическими порогами возникает, как минимум, три проблемы. Во-первых, зависимость от предугадывания снова стучится к нам в дверь: как мы можем знать, какое именно число для порога нам нужно выбрать? Во-вторых, это только одно число! Характеристики производительности приложений в интернете изменяются с каждым часом. Третья проблема не такая критичная: вам, вероятно, хотелось бы знать о том, что система упала еще до того, как она достигнет критичной отметки.
Единственный случай, где пороги могут быть полезны, — это когда вы обещаете что-то третьим лицам. SLA всегда устанавливает определенные границы работоспособности своих систем, например, «Ожидание ответа API не превышает 500 мс». Но это бизнес, а не наука. Выставление удобоваримых лимитов вряд ли поможет нам разобраться, в чем дело. Вы не можете знать, что обычно ломается первым, пока оно не сломается у вас хоть раз.
Мир вокруг нас просто заполнен всевозможными фразами типа «автоматическое определение аномального поведения» или «выявление неисправностей». Быстрый поиск по этим фразам предоставляет огромный выбор между нейронными сетями, методом опорных векторов, методом ближайших соседей и, наверное, еще очень многими методиками.
Самым простым же способом сделать эту работу будет собрать все метаданные и измерения, которые могут оказывать значительное воздействие на производительность системы. Время — первое и самое очевидное. За ним идет тип запроса (например, script_path), оборудование (хостинг, датацентр), версия программы (номер сборки) и так далее. Для каждой комбинации из этих размерностей создайте отдельные метрики, представленные разными порогами: скажем, 25-й, 75-й и 99-й процентиль параметров walltime и cpu_time. Вам нужно иметь информацию того же типа, что и на панели, только с расширенным количеством данных.
Создав эти метрики, вы сможете определить «нормальные» значения для разных временных точек на протяжении дня, исследуя уже собранную в истории информацию. Если 99-й процентиль параметра walltime для /foo.php между 2:20PM и 2:40PM за последние две среды был 455мс, значит, предупреждение должно сработать в случае, если в следующую среду в 2:25pm метрика покажет результат, сильно превышающий ожидания на основе процентного соотношения или чего-то более изысканного, типа среднего квадратического (прим. пер. — root mean square error или сокращенно RMSE).
Сильно – это сколько? Вы можете провести исследование и посмотреть, сколько будет появляться предупреждений и когда их нужно генерировать. Просмотрите записанные данные за прошлый день или неделю и прогоните ваш детектор через них. Насколько щепетильным должен быть ваш детектор — дело ваше.
Мусор на входе — мусор на выходе
Перед тем, как вы обрадуетесь, я хочу вас предостеречь. Если у вас нет уже готовой модели работающей системы, то все это будет результатом обработки не реальных данных, а ваших домыслов. Не спешите. Автоматизируя не обкатанные процессы, вы только создадите плохой, некорректный автоматический процесс.
Очень частая ошибка заключается в перескакивании сразу на уровень создания системы оповещений без проделанной тяжелой работы по определению проблемы и тщательного исследования очень важных особенностей системы, для которой она создается. Время на протяжении дня, день недели — все это очень важные аспекты. Мы может пытаться угадать, какими будут те или иные параметры, но единственный способ знать наверняка — исследовать данные.
Если вы все сделаете правильно, то сможете заменить постоянный просмотр графиков производительности небольшим скриптом. Если ошибетесь — вы создадите автопилот, который поможет вам с треском врезаться в ближайшую гору. Это может случиться и в том случае, если изначальные параметры сменятся. Никто не заботится о DNS, версиях ядра и внутреннем трафике данных пока попадет из-за них в беду.
В любом случае, если вы решаете создать средство обнаружения отклонений от нормального состояния, сделайте его простым. Оно не должно быть умнее человека. Оно должно давать больше информации и легко расширяться при необходимости.
Не останавливайтесь на достигнутом
Что происходит, если графики начинают сходить с ума и срабатывают оповещения? Очень часто несколько предупреждений срабатывают по одной и той же причине, как и наоборот. Например, резкий перепад параметра cpu_time повлечет за собой увеличение значение общего времени загрузки страницы (walltime). То же происходит и с базами данных, когда при увеличении ожидания ответа от базы, увеличивается и время обработки запроса. Один из способов избежать этого — постараться исключить пересечение параметров, особенно во времени.
Еще один способ сделать систему оповещений немного умнее, научить ее глубже анализировать данные. Как только соблюдаются условия для оповещения, скажем, общее время загрузки страницы перевалило какой-то порог, ваша система будет быстро перебирать разные комбинации на предмет того, имеет ли проблема более локальный характер. Скажем, по датацентру или типу пользователей. Эта система немного схожа с той рекурсиной системой поиска, которую мы обсуждали в предыдущих главах этой книги.
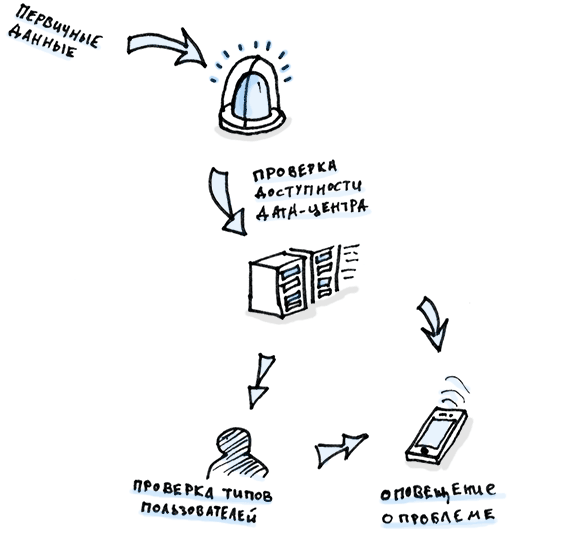
Тут вас ждет много рутинной работы: для начала нужно определить сами проблемы, а потом по каждой из них выделить проблемные места.
Скрытые выгоды изучения систем подобной этой заключены в том, что по ходу ее построения вы обнаружите массу проблем, ошибок измерения и калькуляции. В принципе, использование всех данных, а не только рассматривание точек на красивых графиках, будет похоже на комплексный тест для кода программы измерений. И как только вы все поправите, вы не сможете не признать того, что в системе, которую вы измеряете, все намного сложнее, чем вы ожидали. Даже если все пока работает «нормально».
Успешно используя компьютер, вы, как правило, выполняете равносильную работу, не ту, что раньше... наличие компьютера в долгосрочной перспективе изменило характер многих экспериментов, которые мы проводили.Ричард Хэмминг, Искусство научного исследования и изобретения