Визуализация
Четырехлетний ребенок может понять этот доклад! (Беги и найди мне четырехлетнего ребенка. Никак не могу понять, с чего тут нужно начинать.)Гроучо Маркс, Duck Soup
Настолько же, насколько очевидна польза правильно названных и перепроверенных исходных данных проверок производительности, настолько же они неприглядны для обычного человека.
Продолжайте использовать то слово
До сих пор мы все время усредняли значения данных проверок. Легко понять, как посчитать среднее арифметическое функцией avg(): берем сумму всех чисел и делим ее на количество слагаемых. Но усреднения обманчивы. Как только Бил Гейтс входит в автобус, в среднем, каждый пассажир автобуса — миллиардер.

Взглянем на метрику среднего времени загрузки страницы (walltime per hit). Среднее время загрузки DERP, исключая наши проверки сервера, — 439 миллисекунд. Звучит медленно? А реально ли это медленно? Какие именно страницы портят статистику? Трудно проверить.
sqlite> select round(avg(walltime)/1000), count(1)
from derp where script_path != '/health';
439.0 | 3722
Давайте разделим значения на 10 участков, по 100 миллисекунд каждый, в которые будем записывать, сколько процентов запросов попадает в тот или иной отрезок времени загрузки страницы.
select round(walltime/1000/100) * (100) as bin,
round(count(1)/3722.0, 2) as percent
from derp
where walltime/1000 < 1000
and script_path != '/health'
group by bin;
0.0 | 0.41
100.0 | 0.17
200.0 | 0.1
300.0 | 0.06
400.0 | 0.04
500.0 | 0.02
600.0 | 0.02
700.0 | 0.02
800.0 | 0.02
900.0 | 0.02
Эта приблизительная гистограмма показывает нам, что 40% всех наших запросов вписываются в отрезок 100 миллисекунд. В этом списке это не очевидно, но вообще сумма всех процентов приблизительно равняется 88%, то есть много запросов вообще вываливаются за границу 1 секунды.
Этот запрос не выдает перцентили. Срединный или 50-й перцентиль (p50), это максимальное число миллисекунд, больше, чем половины запросов. Так как первые две строки в суме дают 58 процентов, мы можем догадаться, что наш срединный показатель колеблется где-то в районе 100-200 миллисекунд.
Поиск срединного показателя (и любого другого перцентиля) не является сложным и дает более точный результат. Просто разбейте ваш результат на большее количество строк и начинайте суммировать их от самого первого и до тех пор, пока не дойдете до 50% (25% или 95% и т.д.). Это все еще приблизительное значение, но погрешность намного меньше. В нашем случае, это значение колеблется между 120 и 135 миллисекундами. 75-й перцентиль же близок к 405 миллисекунд.
select round(walltime/1000/15) * (15) as bin,
round(count(1)/3722.0, 2) as percent
from derp
where walltime/1000 < 1000
and script_path != '/health'
group by bin;
0.0 | 0.0
15.0 | 0.02
30.0 | 0.1
45.0 | 0.11
60.0 | 0.08
75.0 | 0.06
90.0 | 0.05
105.0 | 0.03
120.0 | 0.03
135.0 | 0.03
150.0 | 0.02
165.0 | 0.02
...
Так что за старым добрым средним значением прячется намного больше, чем может показаться. 75% всех запросов показывают результат ниже «среднего». А большинство вообще показывают около 40-60 мс, что в десять раз меньше, чем вы бы думали, если б поверили среднему значению. Даже в обычном SQL нашлись инструменты для выяснения сего факта.
select (walltime/1000/20) * (20) as bin,
replace(substr(quote(zeroblob(
(round(count(1)/11) + 1) / 2)), 3,
round(count(1)/11)), '0', '-')
from derp
where walltime/1000 < 400
and script_path != '/health'
group by bin;
0|--
20|-------------------------
40|-----------------------------------------------
60|------------------------------------
80|----------------------
100|------------------
120|----------------
140|-------------
160|----------
180|----------
200|-----------
220|-----------
240|---------
260|------
280|-------
300|----
320|---
340|-----
360|--
380|--
Предупреждаю сразу, что так лучше не делать. Конечно, с упорством маньяка можно, вывернувшись на изнанку, обойтись в инструментарии одним SQL prompt, но в наши дни это делать не обязательно.
Меньше картинок — больше гибкости
Может показаться парадоксальным, но чем меньше типов визуализации, тем лучше. Задача не ограничивается красивыми картинками, она немного шире. Средства визуализации должны обеспечивать простоту исследований, которая в свою очередь зависит от сочетаемости характеристик. Метаданные в 10 колонках можно представить в виде 10-мерного пространства с одним или несколькими измерениями, помещенными в него. Главная наша задача — помощь пользователю в навигации и сбережение места.
Главный акцент нужно ставить на объяснении динамики и поиску корреляции между разными мерностями. Вообще, если вы понимаете, что вам приходится считать что-то в уме, сравнивать показатели на графике или, еще чего хуже — сравнивать отдельные графики, значит, ваш инструмент нуждается в доработке.
Начните с обычной таблицы. Все измерения видны в колонках, а в каждом ряду — отдельный образец. Первым усовершенствованием может стать возможность прятать ненужные колонки. Вторым — группировка данных по значениям в метаданных. Третьим — просчет метрики (количество, средние показатели, перцентили) для сгруппированных строк. Четвертым — сравнение двух таблиц между собой, с просчетом разницы показателей в каждой из ячеек. Это может быть использовано для сравнения производительности разных датацентров, версий программ или чего-либо еще.
Пока все, что мы сделали, ничем не отличается от динамических таблиц (на самом деле они намного более мощный инструмент, чем может показаться на первый взгляд). Одна из особых размерностей наших данных — время. Узнать о времени выполнения того или иного запроса должно быть возможно в минимальное количество кликов, нажатий клавиш или мыслей об этом. Люди плохо понимают исходные значения времени, но очень хороши в пространственном мышлении. Я для себя определился, что лучше использовать относительные временные показатели, например, «час назад», «на прошлой неделе».
На заданном отрезке времени, скажем, в один час, просчитайте средний cpu_time, разбив его поминутно. Вы можете представить результат в виде таблицы, в каждой строке которой был бы один минутный отрезок, но для пользователя это будет выглядеть очень сложным для восприятия. Самое время добавить еще один тип визуализации — график временного ряда. Мы уже часто его использовали в этой книге, так как убеждены, что очень важно показывать изменения время от времени.
Добавляя новый тип визуализации, нужно обеспечить ему те же дополнительные функции, что и в предыдущем: возможность скрывать колонки, группировка, расчет метрики и демонстрация различий. В графиках временного ряда это может быть осуществлено добавлением еще одной линии как здесь:
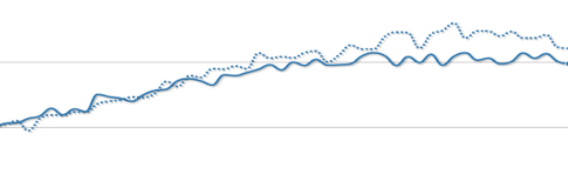
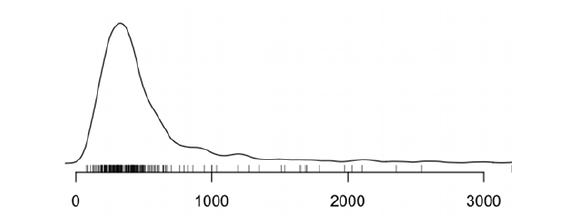
Еще одним важным типом визуализации являются гистограммы. Их задача — показать распространение значений заданных образцов, прямо как на простецком SQL графике, который мы делали ранее. Сравнивать гистограммы немного сложнее, но это стоит того, чтоб поэкспериментировать и найти что-то, что вам нравится.
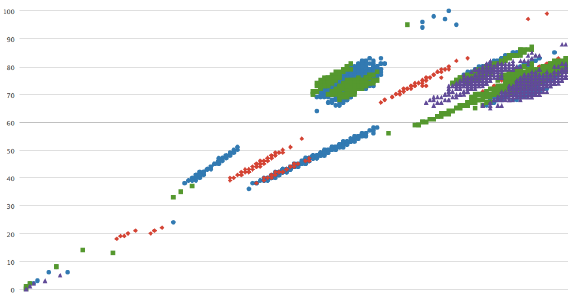
Четвертым типом является диаграмма разброса или график рассеяния. Очень редко метаданные могут быть полностью независимыми и диаграммы — самый простой способ показать эти самые зависимости между ними. Вот, к примеру, график, на котором показана связь между использованием процессора и производительностью на разном количестве серверов. Зависимость почти линейная, чего и следовало ожидать от системы, которая завязана на процессоре. Тем не менее, есть некоторые отклонения, которые очень интересны. Вероятно, они обусловлены разными чипсетами, памятью и степенью загрузки.
Цепочка аргументов
Другой важный принцип — это использование цепочки аргументов вместо простого взгляда на данные. Для того чтобы отыскать ответ на вопрос, пользователь, вполне вероятно, прибегнет к нескольким запросам, возможно, возвращаясь к предыдущим, вращаясь вокруг одной размерности метрики или даже отступая на пару шагов назад.
Ваша система должна быть построена на принципе управления комбинаторным взрывом возможных метрик и взглядов на данные. Только некоторые из них важны, а исходные данные быстро устаревают. Так что каждый запрос, сделанный пользователем, должен быть сохранен: не только описание запроса, но и все данные, полученные в результате. Если сделать все правильно, это займет всего-то с десяток лишних килобайт на запрос. Присвойте каждому такому запросу свой уникальный адрес, которым можно в случае чего поделиться с кем-то еще. Набор из таких вот ссылок и есть звено в цепочке аргументов.
Идеи этой главы — это только примеры того, как можно отобразить данные. Чтобы выжать как можно больше из ваших драгоценных данных, применяйте новые подходы, основанные на поведении пользователя. Если усилия пользователя были оправданны, оправданны будут и ваши.