Правильный способ ошибаться
Лучше плохо исправлять нужные вещи, чем хорошо исправлять ерунду.Ричард Хэмминг, Искусство научного исследования и изобретения
Если вы следуете всем правилам, четко проводите измерения, но это все равно не срабатывает, то, возможно, вы неверно определили саму проблему. Возможно, вы измеряете совсем не то, оптимизируете неверный уровень стека или ошибаетесь в первопричине. Такое случалось и в HHVM команде Facebook. Этот конкретный случай — редкость, такое случается не часто, но подобное происходит каждый день.
HipHop Virtual Machine (HHVM) — это виртуальная машина для языка PHP. Время от времени она использует динамически генерируемый байт-код (just-in-time или сокращенно JIT), работающий медленно, но большую часть времени он обрабатывает быстрый, предварительно скомпилированный код C++. Реализация не была полностью завершена, однако уже были реальные предпосылки сделать производительность главной фичей машины.
Они начали с того, что определили проблему, в точности, как мы поступили с WidgetFactoryServer. Просто нашли функции, которые отбирают больше всего процессорного времени, и оптимизировали их. Но это сработало не так, как ожидалось.
HHVM сегодня раза в три быстрее, чем год назад. Тогда, как и сейчас, она тратила приблизительно 20% времени на JIT и 80% на C++.
Вот удивительный факт, заслуживающий того, чтобы его тщательно осмыслить и, надеюсь, понять: такие внушительные результаты были достигнуты в результате оптимизации кода, отвечавшего всего за 20% процентов общего процессорного времени. Остановитесь здесь и перечитайте этот абзац еще раз.
Представить себе, что такое может случаться в реальных приложениях, за которые вы несете ответственность. Это вам не мелочь какая-то, это трехкратная разница в производительности.
Изучение тех участков кода, которые больше всего используют процессорные ресурсы, позволит вам найти места, нуждающиеся в оптимизации. Советы начинающим программистам в области “непродуманной оптимизации” с разрешением профилирования, в общем-то, неправильные. Хотя это может уберечь их от еще более неправильных подходов в оптимизации.
Кит Адамс
Что же случилось? Как у них поучилось добиться такого результата, игнорируя 80% кода? Все из-за того, что малые участки кода оказывают воздействие на большие. Изменения в коде JIT, номинально представленного только 20% процессорного времени, повлекло случайные эффекты по всей системе.
Для того чтобы понять, почему так происходит, запомните, компьютер делает только две вещи: читает данные и записывает данные. Чем больше нужно обрабатывать данных, перемещать их с места на место, тем ниже производительность. Пропускная способность канала и задержки всегда играют свою роль. Включая процессорные инструкции, биты и байты программы, на которые мы обычно не обращаем внимания.
На самом деле, конечно, не все так просто. Но все компьютеры в той или иной степени являются эквивалентами Машины Тьюринга. А что она делает? Перемещает символы на ленте.
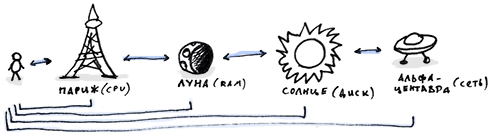
Те компьютеры, что мы используем сегодня, имеют 4 основных уровня, на которых данные «перемещаются с места на место» и каждый из них в сотни тысяч раз медленнее предыдущего по мере отдаления от процессора.
- Регистры и процессорный кэш: 1 наносекунда
- ОЗУ: 102 наносекунд
- Локальный диск: 105 — 107 наносекунд
- Сеть: 106 — 109 наносекунд
Контроллеры памяти стараются удерживать весь первый уровень заполненным данными, потому что каждый промах кэша заставляет вашу программу уходить на сотни штрафных кругов. Даже с 99% попаданий, большая часть времени будет потрачена на ожидания данных от ОЗУ. То же происходит и с огромным, как пропасть, временем ожидания между оперативной памятью и жестким диском. Распределенные системы всегда предпочитают использовать локальный диск вместо сети и так далее.
HHVM в основном использовал подкачку на процессоре. Машинный код — тоже данные, которые должны отправляться процессору на исполнение. Какой-то код JIT копировался в кэш и замещал собой предыдущий. Потом, снова передавал контроль среде C++, строки кода которой уже были замещены в кэше кодом JIT, что заставляло процессор ждать подкачки кода из ОЗУ. Выяснить это было нелегко, если не сказать больше.
Эффекты, связанные с кэшем, всегда очень тяжело поддаются объяснению, отчасти из-за того, что всевозможные кэши являются местом причудливого действия тел на расстоянии. Кэш является структурированным ресурсом коллективного пользования, которое объединяет нелокальные участки вашего кода; ветвь кода
Аможет быть быстрой сегодня только потому, что кэш-строка, с которой он работает, остается в кэше на протяжении большого количества времени.Изменения в несвязанном коде, приводящие к тому, что теперь он будет занимать в кэше 2 строки, могут внезапно заставлять код
А«промахиваться» каждый раз. ЕслиАважен, то «невинные» поправки могут привести к катастрофе.Реже случается обратная ситуация, вызывающая еще большее недоумение, так как вы не можете понять, что приводит к изменениям производительности программы. Еще в самом начале разработки Джордан Делонг провел некие манипуляции с JIT кодом, что неожиданно дало 14% прирост (!!!) производительности в целом.
Кит Адамс
Поверхностной проблемой было процессорное время. Но большей частью оно тратилось не на вычисление (перемещение данных внутри процессора), а на запрос и обработку данных из ОЗУ. К тому же, профилирование (и даже такие программы как VTune или модуль perf в Linux) было практически бесполезным. Оно указывало на то, что большинство функций не используют кэш процессора, но не говорило, почему.
А потому разработчики пришли к новому определению проблемы, которое в целом сводилось к следующему:
Доминирующим фактором производительности HHVM является неиспользование процессорного кэша. Если мы отследим функцию, которая не смогла найти нужные данные в кэше, а также функцию, которая перетерла эти данные, то заметим, что только небольшое количество функций создает проблемы. Если мы оптимизируем эти функции так, чтобы они использовали меньше места в кэше, у нас, в итоге, должно снизиться количество таких случаев и уменьшиться общее процессорное время.
Немного сложно для понимания, но это сработало. Чтоб доказать эту теорию программисты начали собирать сложные и детальные логи, например, все обращения или выполненные процессорные инструкции. Далее, они «скармливали» все эти логи симулятору кэша, изменяя симулятор для отслеживания всех путей от замещаемого к замещаемому для нахождения функции-виновницы. Сортировали список так, чтобы было видно самых злостных нарушителей для последующей оптимизации. Процесс не из легких, но, тем не менее, выполнимый.

Подведем итог. Все хотят использовать готовые рецепты, и чаще всего они доступны. Но как создаются новые? Это происходит тогда, когда все остальные попытки провалились и вам нужно самостоятельно искать пути решения проблемы или даже само ее определение.