Инструментарий
Вы знаете мой метод. Он базируется на изучении мелочей.Шерлок Холмс, Тайна Боскомской долины
Как вы анализируете код? Как измеряете показатели? Ответ кроется в самом узком месте программы, которую вы исследуете, но главное – это подобрать правильные инструменты. Поле для самообмана здесь очень велико. В этой главе мы сосредоточимся на методах сбора сведений о производительности. Для чего она нужна, и что с ней делать, мы обсудим потом.
Начнем с того, что определимся с понятиями.
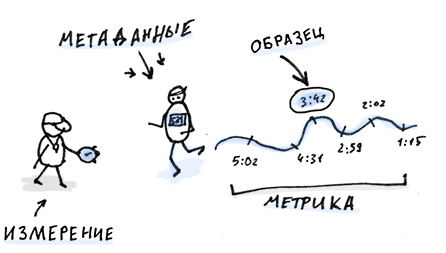
Измерение — анализ чего-либо, на выходе из которого мы получаем число. Это может быть количество итераций процессора или время, требуемое для выборки данных из памяти, число полученных или отправленных битов и т.п. Практически всегда это целое число, потому что мы имеем дело с дискретными системами. Если на выходе вы получили дробь, это произошло из-за используемых систем исчисления (34,19 миллисекунды = 34190 микросекунды) или потому, что это не одиночное измерение, а среднее арифметическое чего-либо, как, например, температура процессора или объем чего-то в секунду.
Метаданные — это атрибуты системы, наличие которых может влиять на интерпретацию полученных данных. Они включают в себя фактор среды, например, временные метки, имя компьютера, версию компилятора, тип проведенной операции. Они также включают в себя не численные данные, полученные во время измерений. Такие, как названия ошибок. Метаданные помогают вам разобрать бесформенную массу данных на четкие, связанные между собой группы.
В науке, изучающей системы и шаблоны распознавания, они называются компонентами. В анализе размерностей — размерностями. В физике вы можете заметить, что они называются номинальными, критичными, или атрибутивными переменными. Все это, так или иначе, — одно и тоже.
Образец — это набор измерений и метаданных, полученных при исследовании какого-то одного события. Это описание события, обычно, операции, произведенной устройством. Вообще-то, «образец» также означает небольшую часть большой серии измерений, например, 5% всех жителей планеты. Чтобы не путаться, в этой книге термин «образец» будет означать исключительно описание одного события.
Метрика — это описание набора образцов. Обычно это суммарное количество всего, что поступило после измерений, включая описания каждого составляющего в отдельности. «Среднее время обработки запросов WidgetFactoryServer между 10 и 11 часами утра 18 апреля 2013 года в датацентре на западном побережье США составило 212 миллисекунд». Метрика также может просто вычислять пропорции, например, «в случае 1,22% всех обращений приложение выдало ошибку».
Компьютеры похожи на луковицу
Правильная оптимизация делается поэтапно. Избегайте искушения сделать первое, что пришло вам в голову. Может показаться, что лучше начать с того, что получается лучше всего, но это ощущение обманчиво. Мы занимаемся оптимизацией только после тщательных измерений. Некоторые вещи делаются проще остальных и именно поэтому люди уделяют им намного больше времени, чем нужно.
В принципе, эта книга слишком мала, чтоб обсуждать клиентскую часть приложения, поэтому мы сосредоточимся только на серверной.
Забудьте о том, что это вы написали программу, и начинайте с базовых вещей. Представьте ее как инопланетный объект, свалившийся на вас с небес. Вам нужно еще разобраться в том, как именно она работает. Не что она делает, а как. Какие данные она использует на входе? Что мы получаем на выходе? Как и когда это происходит? Лучше всего начать с базовых показателей «давления и температуры» вашего приложения. Потом вы будете дополнять их детальными описаниями самых «горячих» мест вашего приложения. Это процесс рекурсивного отбора данных для поиска скоплений важных данных для оптимизации.
Ваш инструментарий должен прорабатывать все возможные сценарии использования программы. Проводите всевозможные измерения, но они не должны противоречить информации, полученной из реального мира. Основной смысл таков: все измерения, проведенные вами на рабочем месте, и теории, основанные на них, могут быть подвержены сомнению, то есть, вы можете лишь максимально приблизить условия эксперимента к реальному миру, но не можете его подменить полностью. Единственный способ проверить ваши теории — проводить тесты и после выпуска программы.
Допустим, у вас есть какое-то серверное приложение. На уровне веб-сервера – хранилище данных и, наверное, уровень кэширования. На уровне веба всегда происходит больше всего процессов. Даже если узкое место приложения находится не здесь, все равно этот уровень всегда имеет определенные рычаги. Базовый лог каждого посещения не обязательно должен быть сложным, хватит перечня ресурсов, задействованных во время запроса. Вот пример, смоделированный на реальной системе:
Metadata
timestamp script_path
server_name status_code
datacenter ab_tests
build_number user_id
Все это должно быть легко доступным на уровне приложения. Часто ошибочно программисты собирают слишком мало метаданных. Каждый кусок информации, который поможет вам разобраться или отделить один образец от другого, должен записываться. Записывание логов поможет вам зафиксировать ошибки, не перегружая при этом HTTP запросы. Записывая всю информацию из A/B тестов, вы сможете экспериментировать с разными видами оптимизации. Если вы собираете логи с номерами сборок, вы можете сопоставить изменения в быстродействии с изменениями в коде.
К сожалению, script_path не всегда может быть полезным, так как сейчас все реже прослеживается связь между ссылками и скриптом, на который они ссылаются. У меня еще не появилось нормального названия для этого поля, но оно должно отражать содержание большей части того, что происходит с приложением. Если это ссылка на домашнюю страницу, можно оставить в названии путь. Если это запрос на сервер API, в названии лучше написать метод. Если это ссылка на страницу с архитектурой контроллера, в названии следует пометить имя контроллера и т.д. Число объектов класса этого поля должно быть невысоким — максимум несколько тысяч. Если какой-то параметр существенно влияет на поведение приложения, включайте его, но не нужно вписывать туда все.
Measurements
walltime db_count cache_count
cpu_time db_bytes_in cache_bytes_in
memory_used db_walltime cache_walltime
bytes_out
Это вполне достаточный набор полей измерения. В него входит большая часть того, что «потребляет» компьютер (физическое время, процессорное время, память, сеть). Этот набор также включает в себя несколько четких подвидов физического времени: время доступа к базе данных и к кэшу. Включен сбор информации по количеству выбранных и соотношение выбранных к отправленным клиенту данных из базы. Давайте назовем такую систему логов Detailed Event & Resource Plotting (Детальной Схемой Ресурсов и Событий) или сокращенно DERP.
С таким минимальным набором в программе, которая еще не оптимизировалась, мы можем отыскать за пару часов с полдюжины проблемных фрагментов и исправить их. Скорей всего они окажутся в самых непредсказуемых местах.
Добавим еще слоев
Следующий этап нашего анализа подскажет DERP система. Если окажется, что в большинстве случаев нагрузка приходится на процессор, вы можете использовать профайлер процессора для поиска увесистых функций. Если же вместо этого система простаивает в ожидании ответа от базы данных, значит, вам нужно проанализировать все запросы в базу.
Рассмотрим вариант с потерей времени на запросах. Значения параметров db_count и db_walltime в таком случае будут высоки. Значит, вам нужно узнать, какие именно запросы тормозят систему. Подходящим решением будет использовать инструменты самой базы данных для анализа. В большинстве из них есть журнал «медленных запросов» или что-то типа того.
Эти данные вполне могут решить вашу проблему. Просмотрев этот список, вы можете обнаружить вместо нескольких больших тормозящих запросов, много мелких. Может случиться и так, что код, в котором используется тот или иной медленный запрос, найти будет не так просто. Один и тот же запрос может встречаться в разных местах. Закончится все тем, что вы будете плодить метаданные в комментариях к запросам, что породит огромное количество классов и только увеличит энтропию наших данных. Так что давайте сделаем по-другому.
В придачу к сбору запросов к БД и времени запроса на стороне клиента (веб-сервер), собирайте также и сами запросы. Мы оптимизируем количество классов за счет записи их по определенному шаблону. Например, так выглядит обычный запрос:
SELECT photo_id, title, caption, ...
FROM photos
WHERE timestamp > 1365880855
AND user_id = 4
AND title LIKE ''
AND album_id IN (1234, 4567, 8901, 2345, ...)
AND deleted = 0
ORDER BY timestamp
LIMIT 50 OFFSET 51
Мы можем заменить многие из его численных значений своего рода заглушками, так как нет особой разницы в производительности этого запроса, если сменить user 4 на 10 или kayak на sunset. Содержимое в скобках выражения IN мы можем заместить суммой. Вместо серии заглушек типа ([N], [N], [N], [N], [N]) мы можем вписывать туда ближайшее целое число к числу, равному ближайшей степени двойки [N8]. Например, округляя в большую сторону число 5 ([N]) мы получим 8 ([N8]).
Вы можете использовать этот прием для сокращения числа уникальных запросов: уменьшая количество и сортируя уникальные запросы, раскрывая подзапросы и т.п. В самом сложном случае вам даже понадобится небольшой парсер языка. Этот процесс в какой-то степени даже может доставлять удовольствие, если вам нравятся такого рода штуки.
SELECT photo_id, title, caption, ...
FROM photos
WHERE timestamp > [N]
AND user_id = [N]
AND title LIKE [S]
AND album_id IN [N8]
AND deleted = [N]
ORDER BY timestamp
LIMIT 50 OFFSET 51
Структура образцов DERP-DB и DERP практически идентична за исключением того, что DERP-DB описывает только запрос к БД, а не все данные при переходе на страницу.
DERP-DB
Metadata Measurements
timestamp db_walltime
server_name db_bytes_in
datacenter db_query_bytes
build_number db_rows_examined
script_path db_rows_returned
status_code
ab_tests
user_id
db_query_pattern
db_server_name
db_error_code
Зачем же нам одна и та же информация в двух отдельных образцах? Не проще было бы ввести request_id и хранить эту информации только в одном месте, соединяя таблицы по мере необходимости? Или вообще сразу помещать все в один лог?
Такие отдельные логи имеют ряд интересных преимуществ, даже если учесть негативный аспект хранения лишних данных на диске. Вы можете легко представить данные этих логов в виде простой денормализованной таблицы БД, в которой можно быстро находить информацию, что, несомненно, ускорит процесс исследований и тестов на производительность. Также, вам может понадобиться сравнить разницу в производительности между DERP-DB и DERP.
Кэш на бочку
Еще один уровень, который мы можем выделить — кэширование. Это уровень, на котором результаты тяжеловесных запросов хранятся на диске для повторного использования. Как же это все работает? Эффективность кэша зависит от двух показателей: как часто в кэше уже есть данные, которые запрашиваются — hit rate, и как часто эти данные вообще необходимы — efficiency. Есть еще такие вспомогательные элементы как соотношение длины ключа и значения кэша.

Как и в случае с DERP-DB, DERP-CACHE описывает один запрос данных. Необходимы метаданные о том, какие операции были произведены (GET, DELETE, WRITE, и т.п.), ключ запроса к базе, и информация о том, был ли запрос успешным. Предугадывая то, что большинство запросов к БД будут не кэшированными, нам понадобится добавить еще одно поле в DERP-DB для хранения ключей таких запросов.
DERP-CACHE
Metadata Measurements
timestamp cache_walltime
server_name cache_bytes_in
datacenter cache_key_bytes
build_number
script_path
status_code
ab_tests
user_id
cache_operation
cache_key_pattern
cache_server_name
cache_hit
Теперь мы знаем, какие запросы занимают больше всего времени, с каких script_paths они могут приходить, и можем отслеживать эффективность кэша. Процесс оптимизации теперь сводится либо к удалению ненужного запроса, либо к кешированию его результата. В некоторых случаях также и сам запрос нуждается в оптимизации. Только данные от предыдущих исследований могут подсказать, в каком направлении придется двигаться дальше.