Начнем сначала
Таковы мои принципы. Если они вам не нравятся, у меня есть другие.Граучо Маркс (приписывается)
На протяжении всей книги мы опирались на одну точку зрения о природе оптимизации производительности. Время вывести все на чистую воду.
Нашей целью было заставить систему работать надежнее и эффективнее в плане скорости отклика, вычислениях, памяти и т.п. Для этого важны только некоторые участки кода, откуда и термин «бутылочное горлышко». Постоянные системы измерений и изолированные исправления подходят для них лучше всего.
Не очень хорошее определение проблемы. Текст в конце не очень коррелирует с утверждением и является достаточно опровергаемым. Уж очень скользкие эти словечки «надежно» и «лучше всего».
Редукционизм должен быть красной тряпкой для каждого, кто знаком с историей. Случился прорыв. Никто не знает, когда окажется за горизонтом. Сортирующие алгоритмы для увеличения производительности когда-то были серьезной работой, что вызывало у программистов спортивный интерес. Но Тони Хоар придумал алгоритм быстрой сортировки и все прекратилось. Все, кроме возгласов.
После этого появлялись и лучшие идеи, но все они являлись либо развитием основной идеи, либо гибридом с ней.
Прорывы случаются непредсказуемо. Даже если ограничиться не принципиально новыми идеями, а только новыми для нас, мы не можем просчитать, когда ознакомимся с ними. Но мы можем посчитать, сколько раз начать сначала было очень хорошей идеей. Может быть, есть возможность определить, когда потребность в редизайне становится актуальной.

Случайный против фундаментального
Я делю узкие места в коде на две категории. Случайные бутылочные горлышки, с которыми справиться не составляет особого труда. Даже если понадобится хорошо поработать, они не нарушают основных положений архитектуры приложения, а степень их влияния может быть велика. В этом случае нам повезло. Желаю вам много лет приятной работы, имея дело только с этим подвидом неисправностей.
Узкие же места фундаментальной природы убрать непросто, потому что они обусловлены какими-то законами природы или аспектами, вокруг которых вертится вся система. Пределы скорости сетевого приложения обусловлены границей скорости света. Узкое место пиццерии — размер печи. Ракеты ограниченны тем, что тратят топливо на то, чтоб везти топливо.
Как только вы обнаружите такое ограничение, вы должны принять решение, можно ли его убрать, не нарушая всю систему, и стоит ли это делать. Вы должны тщательно взвесить все за и против. Так, мы опять возвращаемся к анализу системы. Решение о рефакторинге должно приниматься, основываясь на технических показателях системы. В теории, вы можете взять любой кусок кода, переписать его на ассемблере и получить в итоге быструю программу… написанную на ассемблере.
NoSQL в SQL
Часто «бутылочные горлышка» являются результатом наличия в коде старого хлама, идей, вокруг которых была построена вся система, но которые потеряли всяческий смысл уже давно. Практики программирования удивительно медленно перестраиваются на новые реалии мира, но вы должны быть осторожны, выбрасывая только устаревшие участки кода. У сервиса обмена ссылками FriendFeed наблюдаются проблемы с БД. Они проделали все стандартные вещи для увеличения размеры данных и трафика: разбиение сервиса на несколько серверов, кеширование, когда это нужно. Оказалось, что во всем этом не наблюдалось особых проблем. Проблема была в том, что их модель было сложно изменить.
В частности, внесение изменений в схему или добавление индексов в базу данных с более чем — 10-20 миллионами строк способно моментально полностью заблокировать базу данных на несколько часов. Удаление старых индексов занимает примерно столько же времени, а решение их оставить снижает производительность. Существует целый комплекс последовательных операций, который поможет вам обойти эти проблемы. Так что, подверженные ошибкам и неподъемные, они, безусловно, отобьют охоту добавлять компоненты, которые будут запрашивать изменения в индексе или схеме. MySQL работает. Она не повреждает базу данных. Репликация работает. Мы уже понимаем ее ограничения. MySQL нам нравится благодаря своему хранилищу информации, а не благодаря шаблонам RDBMS.Брэт Тейлор, Как FriendFeed использует MySQL для хранения schema-less данных
Их бизнес был построен вокруг конкретной базы данных, и эта база стала бутылочным горлышком для оптимизации и добавления новых компонентов. Иногда структуру таблиц было так тяжело менять, что они просто не делали этого. В те года, когда они ее писали, было много привлекательных штук в MySQL и, кроме того, не было особых альтернатив. В итоге, вместо того, чтобы построить новую компанию, они решили отбросить компоненты, которые не вписывались в их «старую печь».
Исходная модель данных FriendFeed, в принципе, соответствовала ожиданиям от релятивной БД, где-то между второй и третьей Нормальной Формой.
CREATE TABLE items (
id string,
user_id string,
feed_id string,
title string,
link string,
published int,
updated int,
...
CREATE TABLE users (
id string,
name string,
created int,
...
Также, они сегментировали таблицы, которые были разбросаны по нескольким серверам так, что, например, предмет с id 1234, который находился в базе данных А, мог находиться там до тех пор, пока в базе Р находился его владелец. Это значит, что все join-ы делались, так сказать, вне таблицы. Запросы в базу разбивались на несколько частей и потом собирались отдельно.
Смысл таблиц, ориентированных на строки, в том, что в них очень компактно хранятся данные. Это в свою очередь делает сложные манипуляции на уровне базы данных более эффективными. Недостаток в том, что изменить их можно только скачав и загрузив снова. Поэтому, если вы не используете эти преимущества, то смысла пользоваться такими таблицами нет вообще.
После долгих тестов и обсуждений, FriendFeed переместил в «набор слов» модель, которая хранилась у них в BLOB и использовали вспомогательные индексы таблиц в мерностях, которые им были нужны. Все мои познания о MySQL ограничивались id объекта и таймстампами (также были автоинкриментные поля первичных ключей, которые содержали в себе порядковый номер добавления в базу данных). BLOB содержали бинарные данные (ужатые объекты на языке Python) про который знало только приложение.
К этому времени у них было хранилище данных ключ-значение, достаточно эффективное для получения объектов, по их id, и, возможно, для получения по их временному интервалу. Они могли изменять схему простым заполнением новых полей в непрозрачной области BLOB. Пока приложение идентифицирует формат, база данных оставлена в покое. Для большей пользы, скажем, для поиска всех вхождений заданного пользователя, они добавили таблицу индексов и заполнили ее.
CREATE TABLE index_user_id (
user_id BINARY(16) NOT NULL,
entity_id BINARY(16) NOT NULL UNIQUE,
PRIMARY KEY (user_id, entity_id)
) ENGINE=InnoDB;
Поскольку быстрое создание или удаление одной таблицы никак не влияет на остальные, процесс происходит очень быстро. У них был фоновый процесс чтения из таблицы понятий и заполнения индексов таблицы. Как только этого добились, получение данных обо всех недавних вхождениях пользователя стало возможным всего за два быстрых запроса:
SELECT entity_id
FROM index_user
WHERE user_id = [S]
SELECT body
FROM entities
WHERE updated >= [N]
AND entity_id IN (...)
Чтобы создать «стену друзей» из недавних ссылок, которыми делились ваши друзья, необходимо скрестить результаты трех запросов:
SELECT user_id
FROM index_friend
WHERE friend_id = [S]
SELECT entity_id
FROM index_user
WHERE user_id IN (...)
SELECT body
FROM entities
WHERE updated >= [N]
AND entity_id IN (...)
Сложные запросы с составными индексами стали набором быстро подбираемых уникальных ключей. Процесс добавления или удаления индексов был отделен от используемого потока производительности. Существует множество разработок, которые можно было бы оформить подобным образом. У большинства запросов есть компонент времени. Добавление метки ко всем индексным страницам должно уменьшить количество элементов, которые нужны приложению для пересечения. Важно, что сейчас можно попробовать сделать все самостоятельно, и сопоставить новую таблицу со старой, и все это не повлечет за собой горьких страданий из-за выходок схем.
Удачными аспектами рефакторинга хранилищ FriendFeed было увеличение предсказуемости производительности системы. Потому что они использовали только нужные индексы с уникальным ключом, только в нужном порядке, диапазон значений времени ответа сервера начал понемногу падать. По большому счету, их система оптимизировалась только в отдельных частях, что порождало большие колебания в производительности.
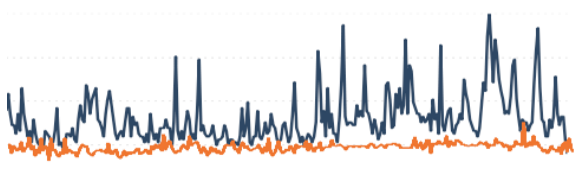
Сокращение колебаний времени отклика вашей системы, даже если это делает средний показатель медленнее — огромная победа, которая оказывает позитивный эффект повсеместно. Это уменьшает возможность серверных «шипов», временных дисбалансов, заполненных очередей и т.д., и т.п. Если бы вы могли магическим образом оптимизировать какую-либо одну метрику в любой системе, то это точно должно было бы быть среднеквадратическое отклонение.