Цепи обратной связи
Галлюцинация — это явление, а не ошибка. Ошибочным будет суждение, основанное на ней
Бертран Рассел, «Природа знания»
Рано или поздно кто-нибудь из вашей команды попытается передать данные системной производительности по каналу обратной связи и научить их реагировать. Эта идея и прекрасна, и ужасна одновременно. Она пришла к нам полностью из сферы автоматического регулирования.
Общая методика окружает нас на протяжении веков. Поплавок в бачке унитаза, поднимаемый уровнем воды и контролирующий уровень воды, работает по тому же принципу. В мире проектирования калибровка замкнутыми циклами используется для того, чтобы убедиться, что принтер отпечатает такое же изображение, какое вы видите на мониторе. У каждого серьезного устройства для выполнения измерений калибровка разработана на основе этой методики.
«Задротство» такого уровня бывает уместно и неуместно. Несмотря на общую корректность, цепь обратной связи для распределенной вычислительной системы имеет три проблемы, которые вам придется решать: время отклика, ступенчатый режим и колебание.
Время отклика указывает на то, как быстро вся система может реагировать на изменения в сохраненных у нее шаблонах откликов. Очевидно, что сбор данных с пятиминутным значением ограничит реакцию вашего цикла до пяти минут, если только вы не просчитаете изменяющийся средний показатель. Также существует задержка распространения сигнала: нам приятно думать, что изменение состояний происходит в одно мгновение. Но чем больше у вас компьютеров, тем меньше это утверждение похоже на правду.
Ступенчатый режим — это свойство, ради которого хочется этим заниматься. Лифты не могут похвастаться множеством режимов отказа. С другой стороны, эскалаторы почти никогда не ломаются. Они просто превращаются в обычную лестницу. Когда ваша цепь обратной связи даст сбой, — а это произойдет обязательно — подумайте, во что она превратится, в ступеньки наверх или в смертельную ловушку.
Колебания происходят от того, что один компонент или несколько компенсируют в избыточной мере. Вспомните те неловкие моменты, когда вы и кто-нибудь другой идете навстречу друг другу. Вы ступаете влево, но через долю секунды он делает то же самое, ступаете вправо — человек снова за вами повторяет.
Адаптивная выборка
Предположим, в пиковые часы трафик настолько высок, что ваша система анализа дает сбой. В результате ваша выборка снижается до уровня, к примеру, 1:10. C другой стороны, если собирать данные в другие часы, их объем будет недостаточным для полноценного анализа. Было бы хорошо оставить объем образцов таким же, но увеличить частоту выборки. В пик уровень доходит до 1:10, в другие часы — 1:3.
Внедрение такого механизма не должно вызвать трудности. Вы отслеживаете изменения и вносите коррективы каждые несколько секунд. Ой! И строите отдельные графики и счетчики для разных датацентров. А еще для параметров script_paths.
Вам понадобится обновлять все образцы на регулярной основе. Задержки между сбором информации и обновлением всех показателей могут занять несколько минут. Если цепочка рвется в полночь, то она может перекрыть цепочку в пиковые часы.
Как по мне, использование цепей обратной связи для выборки — это слишком. Дневной объем трафика вполне известен и предсказуем. Соотношение трафика датацентров к типу транзакций тоже предсказуемо. Вы можете просто взглянуть на данные за последние две недели и построить кривую «коэффициент измерений» с разбивкой на 30-секундные отрезки на протяжении всего дня. Нужно будет лишь пересчитывать показатели каждые несколько недель.
Испытания на нагрузку в динамике
Скажем, вам нужно испытать систему на предмет пропускной способности, например, проверить количество запросов в секунду с каким-то допустимым пределом времени ответа. В версии релиза вы можете доходить до этого предельного значения только максимум раз вдень, а лучше ни разу. Вы можете построить модель в лаборатории для симуляции загрузки, но такой подход имеет ряд недостатков.
Можно взять несколько рабочих систем и подвергнуть их реальной нагрузке. Эффективность системы вы можете измерять в показателе запросов в секунду таких вот загруженных машин. Они могут быть доступны все время для дополнительных тестов, особенно при подстройке конфигураций.
Для начала, определим красную линию, производительность ниже которой неприемлема. Пусть это будет 500мс.
Теперь нужно построить цепь между сервером, который будет подвергаться нагрузке, и сервером, генерирующим трафик. Загружающий сервер будет измерять время ответа на определенном участке. До тех пор, пока время отклика от нагружаемого сервера находится ниже уровня в 500мс, нагружающий сервер будет посылать ему все больше и больше запросов. Как только он перешагнет это отметку, нагрузка будет стихать. Такая система работает достаточно надежно, так как цепь обратной связи в данном случае простая и короткая.
Таким образом, мы снова возвращаемся к системе анализа под названием Dyno, разработанной в Facebook. Она помогает составить график производительности уровня веб-сервера, удерживая константы каждого из факторов: запущенный код, смешанный трафик, компилятор, компьютерное железо, настройки и т.д. Так что вы можете, изменяя одну из них, смотреть, какое влияние это оказывает на отклик системы, измеряемый в запросах в секунду (RPS).
Допустим, у нас появилась новая версия приложения. Вы можете запустить обе версии на сервере параллельно и сравнивать RPS старой и новой в реальном времени.
Глобальная маршрутизация трафика
Знаете, что является самой сложной в мире цепью обратной связи? Да, старый добрый интернет. Если у вас множество датацентров по всему миру, то направление пользователей на правильный датацентр может быть усложнено. Вообще, определение понятия «правильный» уже усложнено само по себе.
На одном уровне система «Cartographer» измеряет задержку в сети между пользователями и несколькими датацентрами по всей планете. Никакой географической информации при этом не используется. В итоге, с каким-то одним датацентром обмен данными происходит быстрее, чем с остальными, так что вы можете перенаправлять пользователя, используя DNS. Эта маршрутизация меняется не очень часто, так что цепи обратной связи держатся в таком состоянии часами, а то и днями.
Но в жизни нет ничего простого. Люди расселены по планете неравномерно, а ресурсы серверов не безграничны. Если сортировать пользователей только по этому принципу, в лучшем случае, сервера будут загружены неравномерно, так как некоторые из них будут находиться ближе к большинству пользователей и наоборот. Поэтому есть еще одно затруднение — располагаемая мощность каждого из центров, заполненных серверами, для отправки туда пользователей.
Цепи обратной связи должны быть способны удовлетворять требования обоих этих затруднений. Это достигается динамическим изменением ответов ваших DNS серверов теми, что имеют распространители доменных имен. Если распространитель 1234 ближе всего к датацентру А, но он перегружен, его адрес подменят так, чтоб он попал в датацентр В, который не так близко, но RPS которого приемлем.
Пока все хорошо. Давайте попробуем написать код. Насколько это будет сложно?
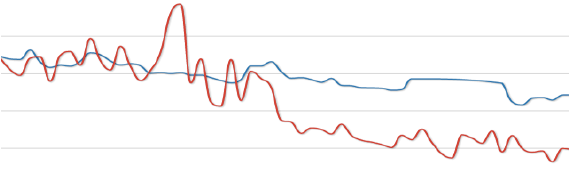
Это было самое лучшее, что я нашел. К сожалению, у меня нет привычки делать скриншоты всего, что я вижу. Оранжевые и синие бегущие линии ранней версии Cartographer. Цепочка обратной связи не была настроена идеально. Это можно было наблюдать. Ошибка Cartographer происходила из-за задержки сигнала от нашего DNS сервера, до сервера измерительной системы. Вместе это все вызывало ощутимые погрешности. Оранжевым помечалась загрузка, а синим — трафик. Затем вдруг случалась инверсия, когда до Cartographer наконец доходили данные. Настолько все было плохо.Алекс Лаславик
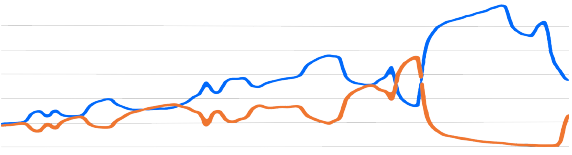
Когда его только запустили, Cartographer начал разносить все больше и больше трафика по сети. Пока Алекс его не отключил. Там были две неисправности, работающие вместе.
Система, измеряющая использование места, была слишком медленной. Сбор данных длился минутами, а их вывод проводился каждые 5 минут. Для Cartographer изменения на карте всегда оказывались неожиданностью, так как замечал он их слишком поздно.
Дополняло проблему еще и то, что ранние версии программы были построены из предположения, что их запросы будут обрабатываться мгновенно. Генерация новых карт и отправка их на DNS сервера была вполне быстрой. Но вот преобразователи DNS были в собственности не Facebook, а ISP по всему миру. В них было встроено много уровней разнородного кэширования.
Чтоб починить цепь обратной связи, следовало исправить время ответа и представления Cartographer’а о том, как работает интернет. Несложные доработки уменьшили время ожидания до 30 секунд, так что Cartographer смог работать с более свежими данными.